
This tutorial will give the reader instructions to setup Hadoop 2.2.0 on Mac OS X with minimal configurations for exercise and development purposes. I have done the installation on my 13-inc MacBook Pro Retina.
Enable Remote Access
- Open System Preferences and click on “Sharing”.
- Select the checkbox next to “Remote Login” to enable it.
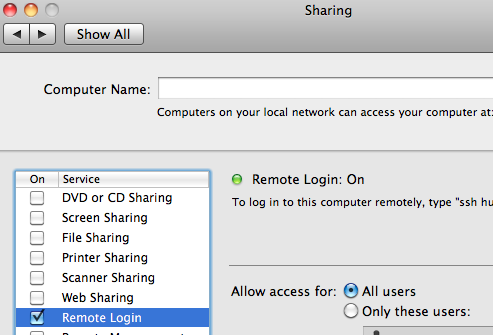

The SSH server will be started in the background.
Configure SSH
$ ssh-keygen -t rsa -P '' $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ ssh localhost
Download Hadoop 2.2.0
$ cd ~ $ curl -O http://ftp.halifax.rwth-aachen.de/apache/hadoop/common/hadoop-2.2.0/hadoop-2.2.0.tar.gz $ tar xzf hadoop-2.2.0.tar.gz $ mv hadoop-2.2.0 hadoop
Set Hadoop-related Environment Variables
$ vi ~/.profile # Add these variables export JAVA_HOME=`/usr/libexec/java_home -v 1.6` export HADOOP_INSTALL=$HOME/hadoop export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop/ export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin
$ . ~/.profile
Configure Hadoop
Create directories
$ mkdir -p $HOME/data/hdfs/namenode $ mkdir -p $HOME/data/hdfs/datanode
Edit etc/hadoop/hadoop-env.sh
export JAVA_HOME=`/usr/libexec/java_home -v 1.6`
Edit etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:8020</value>
</property>
</configuration>
Edit etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/Users/mabduh/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/Users/mabduh/data/hdfs/datanode</value>
</property>
</configuration>
Edit etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Edit etc/hadoop/mapred-site.xml
$ cd $HADOOP_INSTALL
$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Format Name Node
$ hdfs namenode -format
Start Hadoop Services
$ start-dfs.sh $ start-yarn.sh
Run Hadoop Example
$ cd $HADOOP_INSTALL $ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar pi 2 5 Number of Maps = 2 Samples per Map = 5 2013-12-17 17:24:04.985 java[40261:1203] Unable to load realm info from SCDynamicStore 13/12/17 17:24:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Wrote input for Map #0 Wrote input for Map #1 Starting Job 13/12/17 17:24:06 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 13/12/17 17:24:06 INFO input.FileInputFormat: Total input paths to process : 2 13/12/17 17:24:06 INFO mapreduce.JobSubmitter: number of splits:2 ... ... 13/12/17 17:24:15 INFO mapreduce.Job: map 0% reduce 0% 13/12/17 17:24:23 INFO mapreduce.Job: map 100% reduce 0% 13/12/17 17:24:29 INFO mapreduce.Job: map 100% reduce 100% 13/12/17 17:24:29 INFO mapreduce.Job: Job job_1387297380543_0001 completed successfully 13/12/17 17:24:29 INFO mapreduce.Job: Counters: 43 File System Counters FILE: Number of bytes read=50 FILE: Number of bytes written=238825 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=532 HDFS: Number of bytes written=215 HDFS: Number of read operations=11 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=11613 Total time spent by all reduces in occupied slots (ms)=4142 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=36 Map output materialized bytes=56 Input split bytes=296 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=56 Reduce input records=4 Reduce output records=0 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=65 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=481087488 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=236 File Output Format Counters Bytes Written=97 Job Finished in 23.596 seconds Estimated value of Pi is 3.60000000000000000000